
📦 How Containers work? Deep dive into Containerization.
Welcome to Containers Series episode 2.


In our previous post, we looked at how containers have changed the way we ship our software applications over the years. We looked at the difference between virtualization and containerization, and how useful containers are.
We also knew how containers share the kernel and the resources of the host machine.
Well, what does "share the OS kernel"? How do containers really work?
In this week’s episode of The CloudHandbook, we are digging deeper and finding how containers work under the hood.
The CloudHandbook is a reader-driven free Newsletter. Share with your friends and co-workers who might benefit from our posts.
There are 3 core components that makes up the container.
Namespaces
Control Groups
Filesystem
Let’s see the following diagram.

Container technology like docker utilizes namespaces. Docker documentation quotes "Docker uses a technology called namespaces to provide the isolated workspace called the container. When you run a container, Docker creates a set of namespaces for that container."
Although there are other containerization techniques, in this post we will focus on containerization technology that utilizes namespaces. Docker being widely adobpted one in the industry today.
What is namespaces and what does it have to do with containers?
Namespaces is a feature of the Linux kernel that wraps resources in an abstraction making the processes inside the namespaces appear as though they have their own instance of the global resources.
In simple terms, namespaces is a mechanism of isolating processes by controlling the visibility of resources and access control.
When you run a docker container, docker creates a set of namespaces for that container.
pidnamespace: Process isolation(PID: Process ID)netnamespace: Managing network interfaces(NET: Networking)ipcnamespace: Managing access to IPC resources (IPC: InterProcess Communication)mntnamespace: Managing filesystem mount points (MNT: Mount)utsnamespace: Different host and domain names (UTS: Unix Timesharing System)usernamespace: Isolate security-related identifiers (USER: userid, groupid)
Now, let's see what happens when we create a process inside a container.
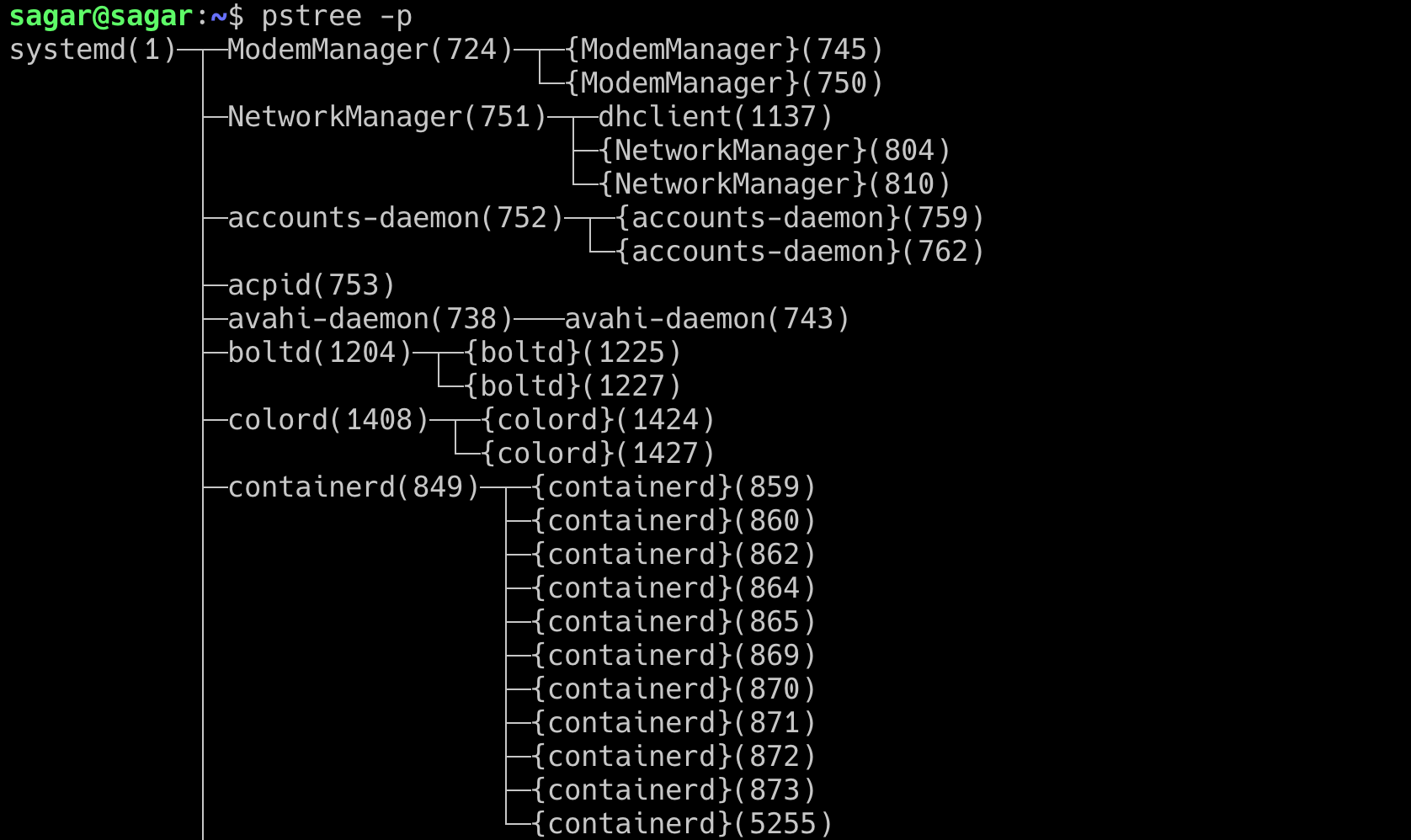
When you run the command pstree -p you can see that the system started with systemd which has the pid of 1. systemd then runs other services as child processes which in turn will run their own child services. One of the child services of systemd is containerd responsible for running the containers.
To see how a process inside a container is created, let’s trace all the syscall and look into the logs In the host machine run
sudo strace -f -p "pidof containerd" -o trace-logIt will then start watching for containerd to run.

Now open up a different terminal and run a Ubuntu container
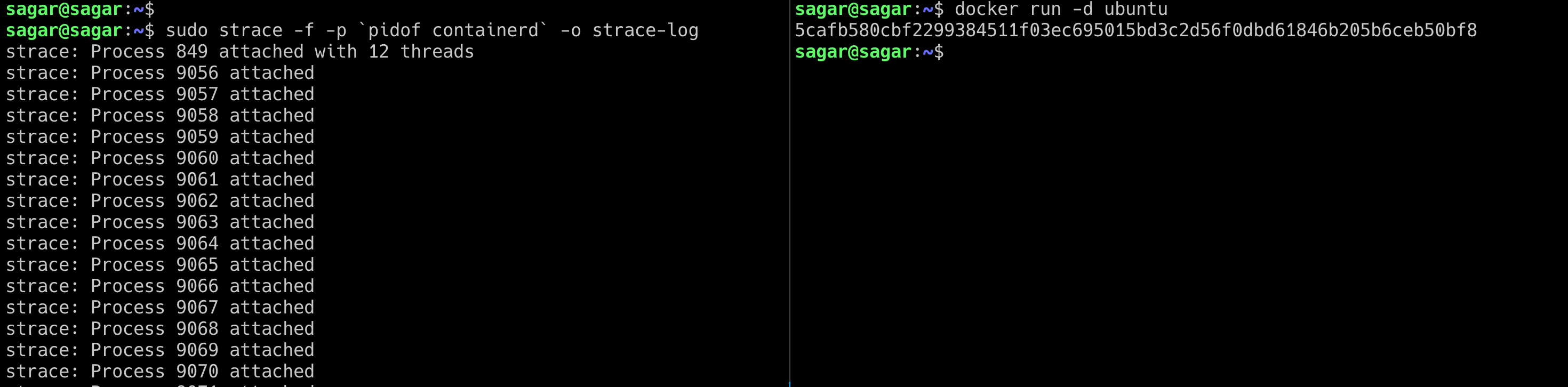
Now you should see the processes attached. If you look into the trace-log file you will see the container is called.

later down the file, we also see that runc is executed which is responsible for spawning up and running the containers.

If we keep looking, a child process of runc having pid of 9091 calls unshare. Note if you're following along, you might get a different pid

unshare creates namespaces for the container to execute processes in isolation.
Looking further down for the same pid you can find a clone syscall which is used to create a new child process. This syscall returns a new pid for the child process in the host.

Now, let's follow the newly obtained pid

Eventually, you'll find a process control call as a child of runc which takes the role of INIT with pid 0. Any new processes that get executed inside the container will be child processes of this process while still having a different pid in the host.
Let's see an example of a process having two different pids in host and a container. Run a shell inside a Ubuntu container.
docker run -it ubuntuInside the container run a watch command to watch running processes every two seconds
root@4f0da96d94ec:/# watch ps axYou'll see

Now, if you run ps ax on the host machine to see all the processes you can see the watch ps ax process with different pid on the host machine.

Remember you just ran the watch command inside the container, not the host machine. But still, it's showing up in the host machine.
All the processes that you run in the container are still running on your host machine. Just in a different namespaces. This enables containers to run in an isolated environment. When we say, "containers share the host kernel", this is what we mean. Any changes made to the process and resources inside the namespace will only impact what's inside the namespace and not impact the host machine unless you share resources with the container.
What is cgroups?
cgroups short for control groups is a Linux kernel feature that limits and isolates the resources and their usage for different processes.
The configurations for cgroups are located at /sys/fs/cgroups
Let's run a docker container with limited CPU resources.
$ docker run -it --cpu-shares 256 --rm ubuntu
# inside the container
$ cd /sys/fs/cgroups/cpu
$ cat cpu.shares
256On the host machine, the cgroups for the container will be inside /sys/fs/cgroups/docker/cpu/<container-id>
cd /sys/fs/cgroups/cpu/docker/45b57315373cc53c725b35ed5550c0a10977f90774dbc018186db4586a53191/
cat cpu.shares
256This is how resources are allocated, limited, and monitored for containers.
Filesystems
Docker utilizes a file system in a layered approach. A docker image is just a set of files containing code, libraries, and its dependencies to run an application. When we create an image of an application on top of another image, this new image inherits the files and directories of the base image and any modifications will exist on the top layer. When you run a container, docker creates a merged view of the file system for the container.
To see how file systems for containers are organized, let’s run an Ubuntu container.
docker run -it ubuntu
cd /
lsYou will see everything in the root directory of the container

Now on the host machine, docker stores these in the overlay2 directory inside /var/lib/docker
cd /var/lib/docker/overlay2
cd 204727a1f4bfccf025789d960c04486792ea01e02820ea02e49b7fbcf6942e3e/merged
lsNote: To figure out which directory the container filesystem is mounted at run cat /proc/mounts | grep overlay inside the container 204727a1f4bfccf025789d960c04486792ea01e02820ea02e49b7fbcf6942e3e

You can see the same files on the host machine. If you create a file inside a container touch hello-world This same file will be created on the host machine.
Wait! The container files still live on the host machine and the processes still run on the host machine. Does that mean the processes inside the container can access files outside of the root directory and modify the host machine?
Not really!!
Here's when chroot comes into play. chroot is an operation on Linux that changes the root directory of a process and any child process. This new environment is called chroot jail. Once we specify the root directory for the process, the processes cannot file outside the root. However, as mentioned here container uses pivot_root instead of chroot the underlying idea are the same.
Conclusion
Although containers have a lot going on, they are made of basic primitives to isolate processes, limit, and monitor. Under the hood, containers and the host machine share the same kernel.
Over to you. How are you using container technologies in your daily life? Let us know in the comments.
 | A guest post by
|
Very informative. Thank you
Thanks!